
11Department of Pathology, Microbiology and Forensic Medicine, School of Medicine, The University of Jordan, Amman, Jordan.
2Department of Clinical Laboratories and Forensic Medicine, Jordan University Hospital, Amman, Jordan.
*Corresponding author : Malik Sallam
Department of Pathology, Microbiology and Forensic Medicine, School of Medicine, The University of Jordan, Amman, Jordan.
Email: malik.sallam@ju.edu.jog
Received: May 28, 2025
Accepted: Jun 13, 2025
Published Online: Jun 20, 2025
Journal: Journal of Artificial Intelligence & Robotics
Copyright: © Sallam M (2025). This Article is distributed under the terms of Creative Commons Attribution 4.0 International License.
Citation: Sallam M. Perspectives on the potential of generative AI to alleviate human idiosyncratic editorial decision-making: If it is broken, fix it now. J Artif Intell Robot. 2025; 2(1): 1021.
The scientific publishing enterprise claims to be a bastion of objectivity and integrity. In theory, it is governed by meritocracy, expertise, and impartial editorial oversight and peer review. However, in practice, it is sustained by a system that has always relied on subjective human judgment which is often compromised by ego, emotion, institutional bias, and cognitive inconsistency. This Perspective article does not mourn a golden age lost; rather, it confronts the truth that editorial decisions have always been vulnerable to the flaws of the human mind. The manuscript argues that the recent emergence of Generative Artificial Intelligence (genAI) presents a historically necessary correction and a chance to realign publishing with its own ideals. Not because genAI is perfect, but because the human editorial class has never been. With inevitability of biased human judgement, the introduction of a machine—cold, consistent, and blind to prestige— referees may be the fairest innovation of all in scientific publishing.
Keywords: Scientific publishing; Human-AI collaboration; AI tools; ChatGPT; DeepSeek.
Ideally, science is the most rational of human pursuits. Yet, the system that governs how it is evaluated—the editorial and peer review processes—remains stubbornly entangled in the very irrationalities it claims to transcend [5,20,34,39]. From its inception, the peer review system has rested on the fragile hope that human editors and reviewers would consistently act as stewards of merit; nevertheless, this hope has proven naïve to say the least [25,41].
Scientific journal editors are often not elected, rarely audited, and seldom held to clearly defined standards of fairness [57]. Additionally, peer reviewers are mostly selected not for neutrality but for availability [58]. In light of this, bias may not always be an anomaly within the scientific publishing system, but at times a feature subtly embedded within it [29]. Prestige often facilitates publication, and publication, in turn, reinforces prestige—creating a self-perpetuating cycle that can unintentionally marginalize less established voices [35,37,50]. For every manuscript that earns recognition on merit, there may be others—equally worthy—that are quietly sidelined by opacity, unconscious favoritism, or the variable attentiveness of editors and reviewers. This concern is not speculative; it is supported by empirical evidence. A recent study by [29] demonstrated a statistically significant bias favoring manuscripts from prestigious institutions, as reflected in higher acceptance rates and shorter review times. Similarly, an earlier study by [56] highlighted how editorial affiliation bias may contribute to—and potentially exacerbate—existing inequalities within academia.
The annals of scientific history are replete with instances where groundbreaking research faced initial rejection by human editors, only to later achieve monumental recognition [6,7]. Such cases expose a deeper, systemic vulnerability: while the editorial and peer review processes were designed to safeguard scientific rigor, they remain inherently susceptible to the limitations of human judgment [13]. Editorial and peer review decisions—shaped by subjective factors such as personal biases, disciplinary preferences, and institutional hierarchies—have too often delayed or obstructed the dissemination of transformative work [6,18,31,59]. These were not isolated misjudgments, but recurring patterns that point to enduring structural flaws in the current scientific publishing system [52,54]. A reexamination of the peer review model, including its susceptibility to bias, is therefore not only timely but necessary [44].
The recent rise of generative artificial intelligence (genAI) marks not merely a technical innovation, but a challenge to long-held assumptions about human judgment [19,30]. Once regarded as little more than imitation, genAI tools like ChatGPT or DeepSeek now demonstrate an ability to write, summarize, and evaluate text with cognitive capabilities that was once believed to be uniquely human [17,47,48]. Among their most unsettling potential is their encroachment into domains traditionally guarded by prestige including scientific editorial evaluation of scholarly work and peer review [8,14,32].
To propose that a machine might one day judge scientific work is not to indulge in futurism—it is to confront a sobering truth: that the human-led model of editorial and peer review, for all its noble intentions, has too often failed to live up to its own ideals [1,23]. To challenge this system is not to romanticize genAI, nor to ignore its frequently cited limitations [45,46]. It is to acknowledge, with intellectual honesty, that inconsistency, bias, and opacity are not occasional flaws but enduring features of the current scientific evaluation process. Therefore, the scientific community is compelled to ask the once-unthinkable: Could genAI—precisely because it lacks ego, fatigue, and favoritism—offer a more impartial standard in editorial and peer review processes? Might the very absence of human qualities make it, in some contexts, more just? This Perspective sought to explore a fundamental question: should we begin to consider whether Large Language Models (LLMs), including genAI tools can act as objective peer reviewers and editorial decision-makers than the humans they were designed to assist?.
To entrust the fate of scientific inquiry to human editors is, in theory, an appeal to expert judgment. In practice, it is an invitation to inconsistency. The assumption that editors and peer reviewers operate under the banner of pure reason ignores an inconvenient truth: human cognition is innately biased [60]. Unlike machines, human beings are not neutral processors of information—they are emotional, fallible, and often blind to their own blind spots [11]. The current editorial evaluation and peer review practices, despite its best intentions, is saturated with well-documented biases that systematically distort editorial judgment [3,24,55]. These distortions are not rare aberrations—they are the rule masquerading as rigor [22]. Figure 1 outlines the principal biases that continue to shape—and at times distort—editorial and peer review decision-making.
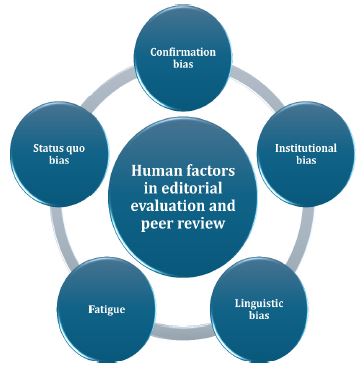
Foremost among human-related biases is confirmation bias, the tendency to favor information that supports pre-existing beliefs and to dismiss contradictory evidence [40]. Academic editors and peer reviewers, consciously or not, are drawn to papers that align with their worldview, methodological preferences, or theoretical frameworks [31]. Novel or paradigm-challenging work often suffers—not for its quality, but for its audacity to question orthodoxy [2]. Closely related is the status quo bias, the aversion to novelty simply because it deviates from familiar territory [49]. This conservatism, often concealed behind the rhetoric of rigor, serves not to elevate science, but to entrench it. A personal example may suffice to illustrate the point: following the submission of a manuscript exploring the early potential use of ChatGPT in promoting vaccination, I received a formal editorial reply from a Scopus- and Web of Science (WoS)–indexed journal stating, “After confirming with the office, we think the software mentioned in this article is really too novel. It was released less than five months ago. We have reviewed articles from WOS and various websites, it is few to talk about the effectiveness of the software. The office felt that there was some risk, so it was not able to continue processing. We hope you can understand” [sic]. The decision to reject a manuscript solely due to the novelty of its subject—as though recency were a weakness—should not be seen as an isolated misjudgment. It is a symptom of an evaluative culture that has conflated caution with integrity, and orthodoxy with quality. In such a landscape, innovation does not fail the test of science; it fails the temperament of the gatekeeper.
Institutional bias—most visibly expressed through the halo effect—remains a pervasive and often unexamined distortion in editorial judgment. Manuscripts originating from prestigious universities or bearing the names of well-established authors are frequently judged more favorably than identical submissions from lesser-known institutions, a pattern demonstrated by [27]. The opposite is equally true: authors affiliated with institutions outside the recognized academic elite often face steeper hurdles to publication—not for deficiencies in their science, but for the perceived modesty of their affiliation [25]. This bias is further compounded by name recognition, which subtly privileges submissions from previously published or frequently cited authors, thereby entrenching existing visibility gaps and systematically excluding early-career researchers from equal consideration.
Another persistent distortion arises from the exhaustion of academic editors and peer reviewers [42]. Faced with mounting submission volumes and limited time, many resort to triage by impression—skimming rather than scrutinizing. In such conditions, superficial markers such as writing style, formatting, and linguistic fluency disproportionately influence editorial decisions. This tendency gives rise to linguistic bias, wherein non-native English speakers are subtly penalized, not for the scientific merit of their work, but for the manner in which it is expressed [43]. The result is a systematic disadvantage that privileges fluency over substance. Compounding this is scope bias, a more evasive form of editorial exclusion. The familiar phrase “not within scope” is often less a reflection of actual misalignment than a euphemism for discomfort with unfamiliar, interdisciplinary, or emerging subject matter—particularly when it falls outside an editor’s immediate disciplinary or ideological domain. These biases, born not of malice but of cognitive economy, nonetheless distort the fairness and inclusivity of the scientific record.
Taken together, these human biases construct a landscape in which fairness becomes the exception rather than the norm. The most perilous assumption in scientific publishing is not that errors occur, but that human judgment is inherently reliable. In such a system, the most rational act of dissent is to seek an arbiter that neither feels, forgets, nor favors—one governed not by intuition, but by impartial design.
Accompanying every episode of scientific revolution, societies have feared that machines might encroach not only upon human labor but upon human judgment [53]. That fear—so often dramatized in fiction and resisted in academia—is not without reason [10,62]. Yet in the context of scientific publishing, it is not the prospect of machines supplanting human editors that should alarm us; rather, it is the sobering recognition that human judgment, long held as the gold standard, may never have been as rational, objective, or fair as we assumed. Unlike its human counterpart, a genAI model does not know who you are. It does not care whether your institution is prestigious or peripheral, whether your name appears frequently in citation indexes or not at all. It does not harbor unconscious biases about geography, gender, or institution. It cannot be flattered. It cannot be provoked. It evaluates structure, not status; coherence, not charisma.
The strength of genAI lies not in creativity or moral sensitivity, but in its very dispassion. It is, paradoxically, its emotional indifference that allows it to serve justice where human judgment often falters [21]. Unlike human editors, who may be overworked, distracted, or anchored by the opinions of the first reviewer, a well-trained genAI tool would apply editorial policies with consistency and precision. If a journal requires structured abstracts, ethical declarations, or adherence to reporting guidelines, the genAI model will enforce these requirements with unerring uniformity. It does not forget, improvise, or selectively apply rules. It does not guess what is “within scope” based on intuition or disciplinary familiarity—it calculates alignalignment using text analysis and semantic modeling [9,33].
That said, no fair assessment would claim that genAI is immune to bias [63]. On the contrary, genAI is shaped by the data on which it is trained and by the assumptions embedded in its design. If those inputs reflect existing inequities—such as the overrepresentation of English-language, Western-centric, or male-dominated citation networks—then the outputs, too, may mirror those distortions. A genAI model trained on such patterns might undervalue innovation from low-income countries or overlook emerging disciplines. However, the distinction lies in accountability. GenAI bias, though real, can be diagnosed, measured, and corrected [28,61]. Unlike human editors, whose biases are often implicit, unacknowledged, and beyond audit, genAI tools can be governed through transparent metrics, feedback loops, and continual retraining. Bias in machines is a technical challenge. Bias in humans is a cultural norm—rarely admitted, much less addressed.
In contrast to the human editor—who may skim an abstract after a long day, bristle at unfamiliar terminology, or dismiss a manuscript based on unconscious assumptions—AI offers a different kind of fallibility. It may be limited, but it is limited predictably. It may make mistakes, but those mistakes are replicable, auditable, and open to correction. This is no small virtue in a process where many authors receive desk rejections without meaningful explanation, or where editorial outcomes depend more on the alignment of personalities than the rigor of content. A genAI editor does not reward prestige, does not retaliate for past disputes, does not forget policy, and does not hide behind vague appeals to “scope” when rejecting unfamiliar work. Even if flawed, it is flawed systematically. And in a system where human judgment is too often governed by fatigue, favoritism, or fragility, consistency is not a limitation—it is a moral improvement [26].
To prefer an AI editor, then, is not to exalt technology above humanity; it is to recognize that dispassion can be a form of fairness, and that the greatest threat to equity in science may not come from machines but from the very human hands that have long claimed to protect it. In this context, the machine we once feared may, in fact, be the fairer judge—not because it is perfect, but because it does not pretend to be.
Contrary to the view defenders of scientific publishing traditions, genAI is not a distant possibility—it is already woven into the fabric of academic publishing [4,12]. The transformation is not theoretical, and it is no longer preliminary. AI is not merely on the horizon; it is already in the room. Leading academic publishers have embraced it, quietly and pragmatically [16,36]. These AI technologies do not represent science fiction; they are functioning tools in an evolving scientific publishing [51]. In the very near future, editorial boards will likely be assisted by genAI models capable of detecting statistical inconsistencies, identifying undisclosed conflicts of interest, flagging citation padding or reviewer manipulation, and estimating the likely societal or clinical impact of a manuscript using semantic analysis [15]. These capabilities are not designed to replace the human editor, but to fortify the process against the inconsistencies and oversights to which human judgment is chronically susceptible. They are not a threat to scientific integrity—they are its recalibration.
When wielded responsibly and governed transparently, genAI tools do what humans, even the most well-meaning among them, often fail to do: apply standards without prejudice, forgetfulness, or fatigue. They do not skip over methodology sections because they are behind on deadlines. They do not allow personal familiarity to influence reviewer invitations. They do not dismiss submissions because the conclusions feel counterintuitive. In short, they bring structure to a process increasingly held hostage by subjectivity.
The age of AI-assisted publishing has begun, not as a rupture with human scholarship, but as a rebalancing of power in its favor. The question is no longer whether genAI will play a role in shaping what is published, but whether we will use its capabilities to correct the known failures of human editorial judgment—or simply replicate those failures in code. The opportunity lies before us. And for those who have spent years navigating an opaque, inconsistent, and often indifferent system, that opportunity feels less like a threat and more like overdue progress.
The future of scientific publishing does not need to be imagined as a contest between man and machine. Rather, it can—and must—be a principled collaboration; a model in which human expertise is guided, rather than replaced, by AI. In such a future, genAI models would serve as guardians of consistency and fairness. These models would handle the initial triage of manuscripts, checking for scope alignment, structural completeness, and adherence to reporting standards. They would suggest reviewers not based on editorial memory or personal familiarity, but on objective expertise and semantic proximity to the manuscript’s content. They would generate structured, first-pass evaluations, reducing the burden of reviewer fatigue and ensuring that every submission receives a baseline level of scrutiny grounded in predefined criteria. The role of the human editor, far from being displaced, would become more focused—reserved for complex interpretative decisions, ethical considerations, and the final arbitration of reviewer disagreement, all made transparently, with editorial names and reasoning documented.
Such a system does not eliminate the human element—it constrains its fallibility. It protects the process from unconscious bias, arbitrary decisions, and the silent erosion of standards by making editorial judgment more accountable. It reestablishes consistency not by algorithmic tyranny, but by systematic fairness. It ensures that every manuscript—whether authored by a Nobel laureate or a postgraduate student in a lesser-known institution—is afforded the same structural entry point into review. It would no longer be acceptable for a manuscript to be rejected based on mood, memory, or institutional prestige. Editorial subjectivity would still exist, but within boundaries defined by transparent inputs and explainable outputs.
This hybrid model—AI as the engine of equity and human editors as the arbiters of nuance—would revitalize scientific publishing rather than threatening the process. It returns to the foundational promise that publication should be governed not by hierarchy, but by merit; not by opacity, but by process. It restores something many have come to doubt ever existed: the right to a fair read.
Choosing the lesser evil, and perhaps the greater good
The editorial process in scientific publishing has long cloaked itself in the language of reason, fairness, and rigor. But when we shift our gaze from its ideals to its actual behavior, a more sobering portrait emerges—one in which the editorial process, rather than embodying objectivity, often reflects patterns of inconsistency. It is a system shaped as much by inertia and gatekeeping as by scholarly excellence. In this light, the proposal to prefer genAI over human editorial judgment is not an act of technological triumphalism. It is, rather, a plea for minimal justice. It is a recognition that the status quo is not only inefficient—it is often arbitrary, unaccountable, and quietly corrosive to the very spirit of inquiry it claims to uphold. To prefer genAI is to choose the lesser evil, and perhaps the greater good. It is to demand consistency where there is now chaos, transparency where there is obscurity, and fairness where bias too often prevails. It is not a call to dismantle human involvement, but to relegate it to the spheres where discernment, not discretion, is truly needed. It is, at its core, a rebellion—not loud, not theatrical, but rational. And if the virtues that science demands—equity, clarity, speed, and accountability—must come from a machine rather than from a man, then let it be so. Let the machine speak, at least because it has no reason to lie.
Conflict of interest: The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Funding: The author declares that no financial support was received for the research, authorship, and/or publication of this article.
